Showcase: LLM Chatbot
Chat is the most common interface for LLM apps. This showcase is a reference implementation on how to integrate Langfuse with chatbots using the Langfuse Typescript SDK.
Demo
Frontend: chat.langfuse.com
Chat application with conversations, user feedback, and streaming responses from the edge.

Langfuse UI
We have captured threads of users as single traces in langfuse. Threads include the user_id, overall token usage, and further metadata. User feedback which is collected in the frontend is directly related to the trace and helps to find low-quality conversations and individual messages which got negative feedback.

Highlights of the integration
- Model agnostic
- Typescript SDK can be used in edge runtimes and in the frontend as it uses the
fetchAPI - Tracing of streaming responses
- Fully asynchronous, adds minimal latency and does not throw errors in the main thread
- User feedback collected in frontend with optional comments on individual messages
Chatbot
We integrated Langfuse into the ai-chatbot template which was open sourced by the Vercel AI team. The template uses (from Readme):
- Next.js (App Router)
- Vercel AI SDK for streaming chat UI
- OpenAI
- Edge runtime
- Chat History, rate limiting, and session storage with Vercel KV
- NextAuth.js for authentication
Integration
The fully integrated showcase is available on GitHub if you are interested: langfuse/ai-chatbot
Backend
We demonstrate the integration via the Langfuse Typescript SDK in app/api/chat/route.ts. This API route handles the streaming response from OpenAI using the Vercel AI SDK and saves the chat history in Vercel KV.
Using Langchain? Read the Langchain Integration announcement to skip the details and integrate in seconds.
Add SDK
npm i langfuseInitialize client
const langfuse = new Langfuse({
secretKey: process.env.LANGFUSE_SECRET_KEY,
publicKey: process.env.NEXT_PUBLIC_LANGFUSE_PUBLIC_KEY,
});Grouping conversation as trace in Langfuse
const trace = langfuse.trace({
name: "chat",
id: `chat:${chatId}`,
metadata: {
userEmail,
},
userId: `user:${userId}`,
});- We use the existing
chatIdas theidof the trace. This allows us to group all messages of a conversation into a single trace. For traces, the Langfuse SDK upserts the trace based on the providedid. This means that we can calltrace()on every new message in a conversation. - We add the
userIdas it allows us to filter and aggregate data in Langfuse based on users for debugging and analytics. - In
metadatawe can add any additional information that we want to be available in Langfuse. In this example, we add theuserEmail.
Creating the LLM call
Before starting the LLM call, we create a generation object in Langfuse. This sets the start_time used for latency analysis in Langfuse, configures the generation object (e.g. which tokenizer to use to estimate token amounts), and provides us with the generation_id which we need to use in the frontend to log user feedback.
const lfGeneration = trace.generation({
name: "chat",
input: openAiMessages,
model: "gpt-3.5-turbo",
modelParameters: {
temperature: 0.7,
},
});Updating the LLM call
Thanks to the Vercel AI SDK, we can use the onStart and onCompletion callbacks to update/end the generation object in Langfuse.
// once streaming started
async onStart() {
lfGeneration.update({
completionStartTime: new Date()
})
}
// once streaming completed
async onCompletion(completion) {
lfGeneration.end({
output: completion
})
}Add generation_id to streaming response
The simplest way to provide the generation_id to the frontend when using streaming responses is to add it as a custom header. This id is required to log user feedback in the frontend and relate it to the individual message.
return new StreamingTextResponse(stream, {
headers: {
"X-Message-Id": lfGeneration.id,
},
});Bonus: Add debug events
The ai-chatbot uses Vercel-KV to store the chat history. We can add debug events to the generation object to track the usage of the KV store.
lfGeneration.event({
name: "kv-hmset",
level: "DEBUG",
input: {
key: `chat:${chatId}`,
...payload,
},
});
lfGeneration.event({
name: 'kv-zadd',
...
}):Frontend
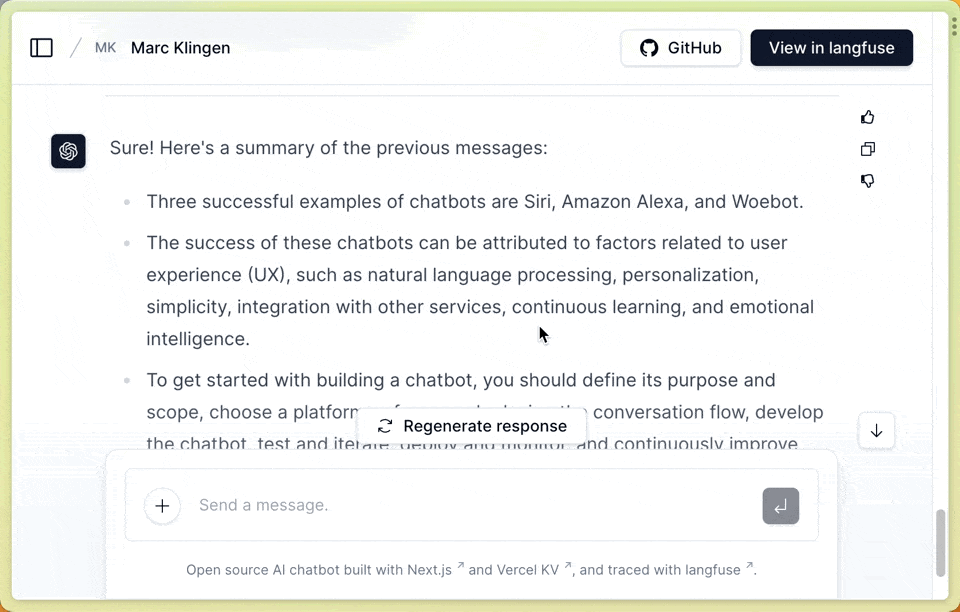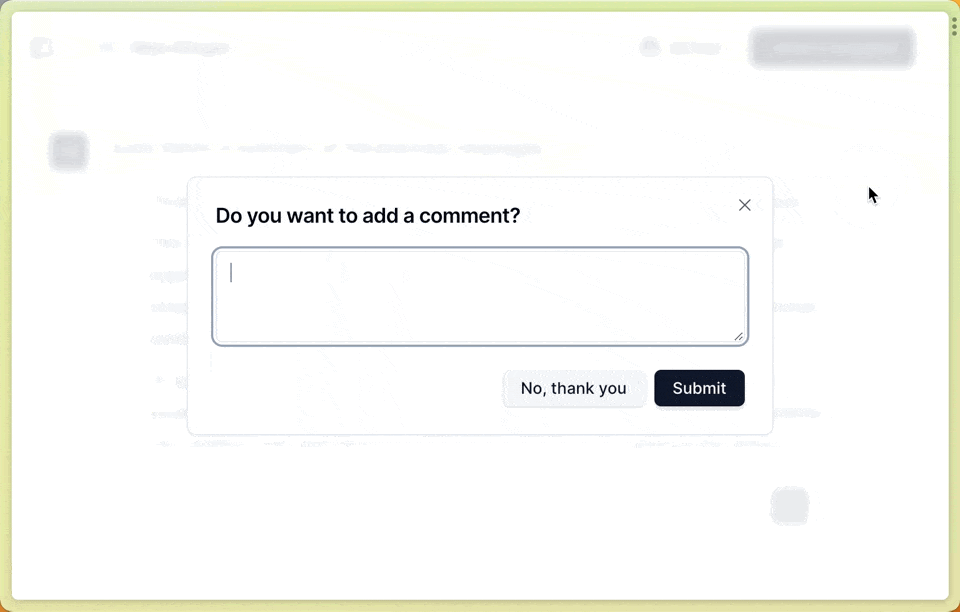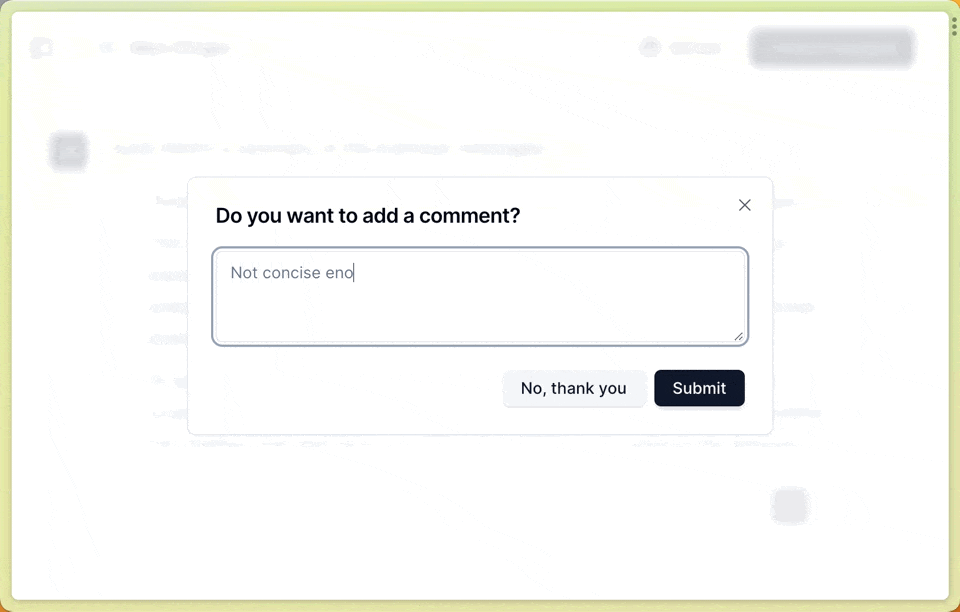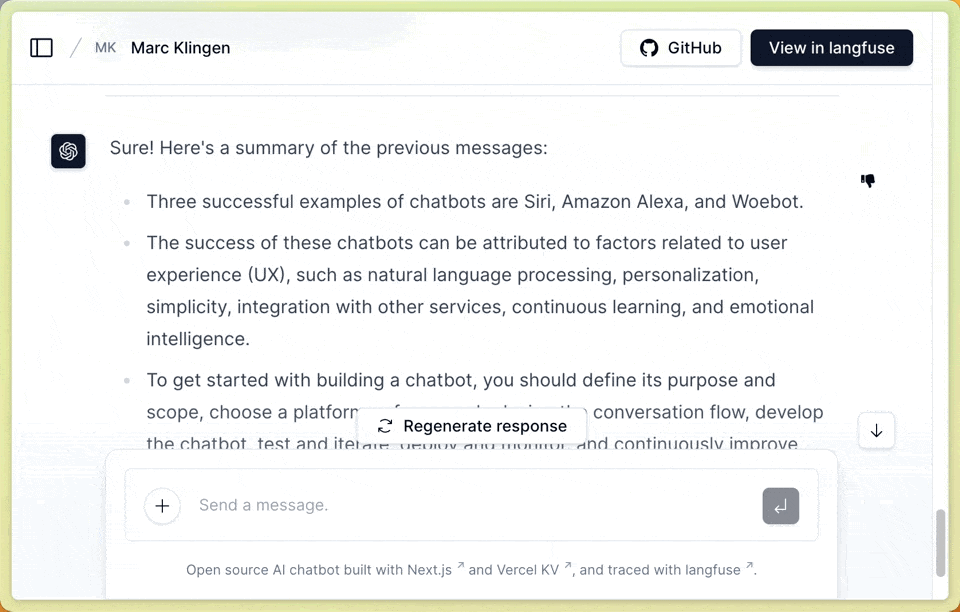
In the frontend, we want to capture user feedback (positive/negative + comment) on a per-message basis. Find the full source code here:components/chat-message-actions.tsx
Feedback modal:
Initialize client
We use the Langfuse Typescript SDK directly in the frontend to log the user feedback to Langfuse.
The SDK requires the publicKey which can be safely exposed as it can only be used to log user feedback.
const langfuse = new LangfuseWeb({
publicKey: process.env.NEXT_PUBLIC_LANGFUSE_PUBLIC_KEY ?? "",
});Log user feedback
We created an event handler for the feedback form. The feedback is then logged as a score in Langfuse. We need to provide two ids to langfuse.score() to relate the feedback to the individual message:
traceId, which is the unique identifier of the conversation thread. As in the backend, we use thechatIdwhich is the same for all messages in a conversation and already available in the frontend.observationIdwhich is the unique identifier of the observation within the trace that we want to relate the feedback to. In this case we made the langfusegeneration.id(from the backend) in the backend available as themessage.id(in the frontend). For details on how we captured the custom streaming response header which included the id, see components/chat.tsx.
await langfuse.score({
traceId: `chat:${chatId}`,
observationId: message.id,
name: "user-feedback",
value: modalState.feedback === "positive" ? 1 : -1,
comment: modalState.comment,
});Next steps
If you want to integrate Langfuse into your own chat application, read the Quickstart for an overview and the SDK documentation for more implementation details.
Get in touch
Langfuse is being actively developed in open source together with the community. Provide feedback, report bugs, or request features via GitHub issues. Join our Discord for fast support. If you want to chat about your use case, reach out to us via email: contact@langfuse.com